
I'm Back! + Fall Tech x Bio Learnings
Questions that continue to provoke us...

After spending a few amazing years in the UK, I’m excited to be back on home turf in the US! Over the last few weeks, I’ve had the opportunity to reconnect with many AI x bio friends: the progress of the industry even in the last few months is prodigious and I’m excited to continue with zest to find and fund cutting edge innovation.
See below on some of the key open questions that bubbled to the top of multiple conversations across investors, pharma, and founders alike:
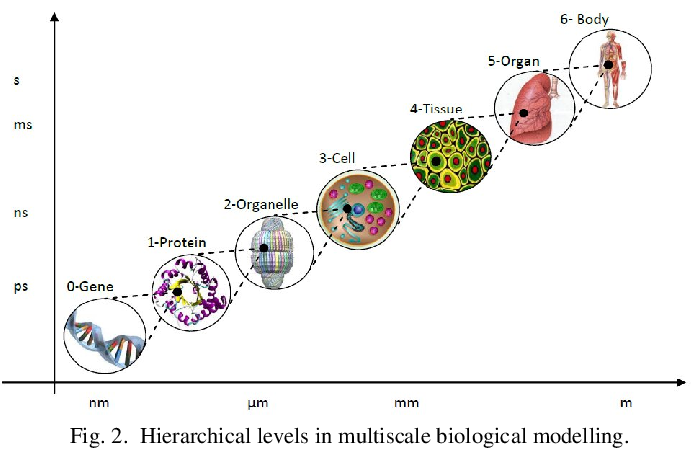
Is the biggest challenge, yet gain, AI can make along the pharma value chain adequately predicting Ph2 clinical results whilst in early-stage discovery? We’ve only really seen the impact of AI in early-stage phase 1 clinical trials (usually boosting success from 40-60% to 80-90%). Multiplying this boost end-to-end, our overall success rate of a drug only goes from 5-10% to 9-18%: probably why there is a lack of true excitement for AI drug discovery in the current climate. Derek Lowe also interestingly notes that most of the current trials tout large-scale efficacy improvements, yet focus on known targets. If we solve a bigger Ph 2 efficacy problem, perhaps through novel targets, we may be able to push up to an overall success rate of nearly 30-50% . Shifting in Ph2 from “molecular fit” to “systems-level prediction” and linking genotype, phenotype, and longitudinal patient outcomes seems around the corner but easier prophesied than enabled due to lack of temporal data. To note, there are very few private companies focusing on multiscale modeling to impact clinical drug development, a space I’m very interested in. Noetik is one of the few pioneers starting first with patient response data from tumor tissue, then working backwards to find appropriate patient groups based on response types. I’m hungry to find other stellar early-stage companies developing systems level integration for multiscale biological models+ clinical development.
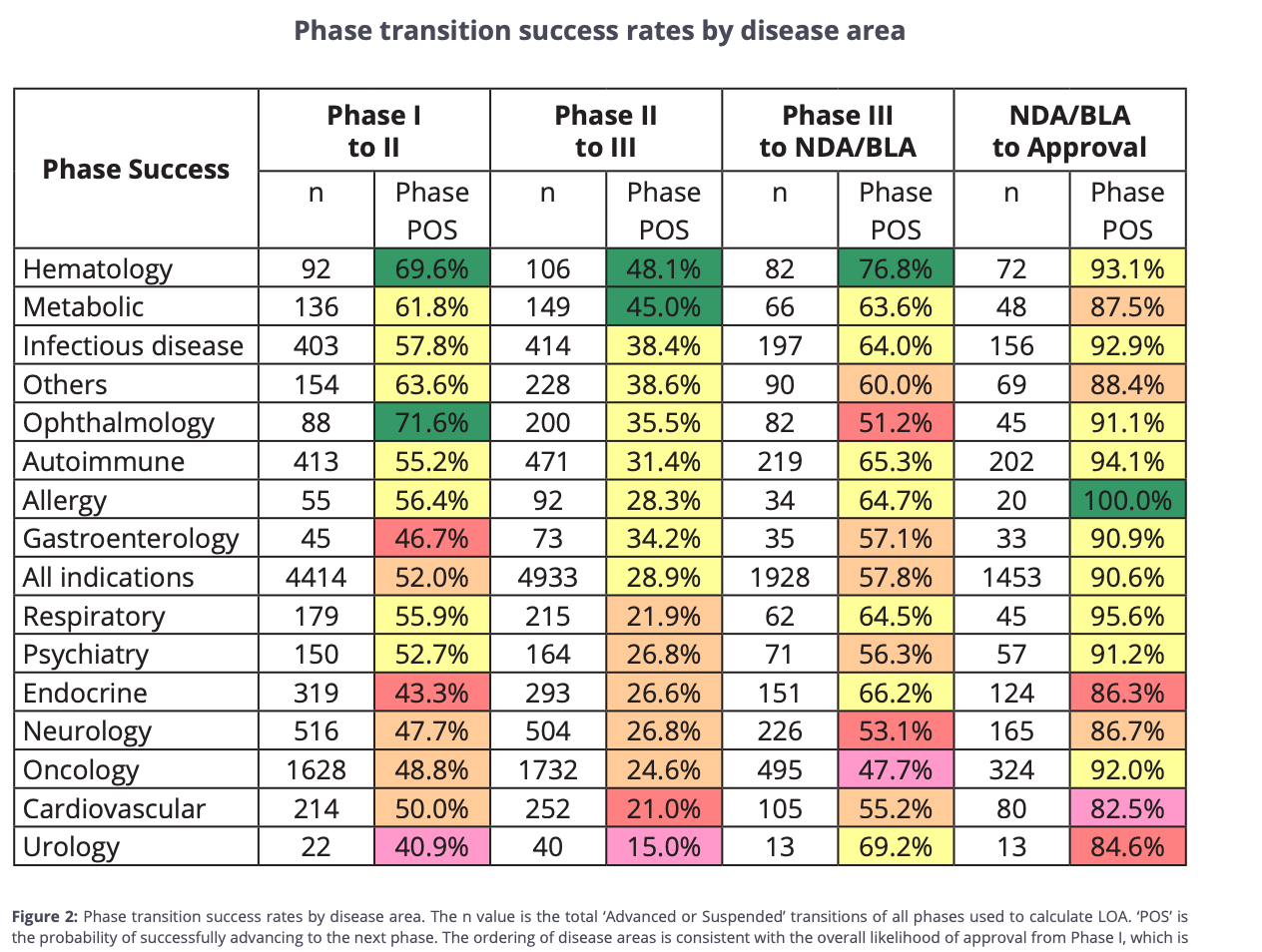
Why are most biotech exits valued only based on drug assets? It boils down to the way capital markets evaluate potential transactions: models are built on cash flows and asset probability of success (PoS) scores. BIO’s 2011–20 data set is what most PoS tables root in; platform-uplift adjustments are ad-hoc. What if there was a world where we modeled on optionality or efficiency (out-licensing options, hitting certain clinical and commercial milestones before an average time metric - see Insilico’s benchmarks)? Would we still need to show multiple commercial asset successes from one platform in order to revisit probability of success scoring, or could there be another benchmark, like time to IND or time to Ph3, we come to consensus on as an industry to adjust PoS?

The age-old question: does a trillion dollar pharma business exist? Perhaps this only occurs through hyper-personalized medicine and/or an intense platform flywheel from clinical through manufacturing and distribution (love Anna Marie’s article here) after the above-mentioned multiple successes… Interestingly, Lilly and NVIDIA are trading at nearly the same P/E multiple (~50x) despite drastically different multiples on revenues (15x vs nearly 66x) and of course underlying market caps. One could hypothesize that 1T is just around the corner (Lilly at ~700B) given the movement we see naturally through inflation, but maybe pharma is simply not an industry where a market cap in the trillions can hold given Capex limitations on net earnings.

Do new FTC guidelines on direct to patient marketing shift all marketing in-house efforts to the HCP? I wrote previously on how we are still far from n=1 physician marketing, but this legislation away from patient-oriented activities may be more of the drive we need to create content that more effectively addresses individual doctors’ (and ultimately patients’) prescribing styles and concerns. Still bullish that there is a world in which we can cut out pharma marketing agency budgets entirely through an AI agent (speaking with a stellar founder in this area, who noted that around 1% of entire brand revenue is on agencies. Even signing on ten blockbusters would make a sizeable market!)
What do less nimble large-cap pharma companies become with our rapid AI-forward trajectory? Are they simply shells for manufacturing hubs and facilities owners? My guess is that they will certainly not cease to play an immense power role but may evolve further into orchestrators as opposed to R&D powerhouses, sitting atop the value chain but less about innovation given lack of agility- more about scale, manufacturing, regulatory, and distribution channels. With this prediction, I’m still keen to find companies innovating in increasing manufacturing efficiency and optimization through real-time sensors, integrated data systems for scale-up, and brick-and-mortar capacity plays. Even more enthused by agents + robotic automation systems with revenue streams outside of R&D- perhaps in GMP manufacturing or bioprocessing scale-up (see new Tesla humanoids deployed for API manufacturing!)

Does pricing scrutiny evolve at all with Makary’s new focus on drug affordability, perhaps a new-found love for economic endpoints in trials, or new ways for longitudinal data to be included in submissions? And will we truly see a world in which PBMs are completely reworked in this new administration + large scale pharmacy benefit data is fully returned to pharma in-house? (I learned over the last few weeks that PBMs right now receive around ⅓ of the US’s 600B prescription drug spending– insane!). TrumpRx , a new direct-to-consumer marketplace that allows Americans to purchase prescription medications directly through the government at discounted prices, is somewhat hilarious in name but may set a precedent for the new DTC world we will live in.
Lastly, does a capitalist mindset hurt or hinder advanced research in the pharmaceutical industry? Are we better off with consortiums to pool data and actually elucidate disease biology or does private competition light the fire novel innovation? I’m enthused about consortiums like Tune Lab, OpenBind, GNPC as the tip of the consortium iceberg, and see a dual model where consortia drives hypotheses (shared data), but therapeutic modalities are competed on, similar to how the semiconductor industry relies on shared foundries but competes on design. Data aggregation could remain in the public domain: exclusivity and QC will have to be clearly defined, though, for this to be workable.
Reach out if you’re building, investing or thinking through any of these areas!